Benetech 대회 회고
대회 링크 : https://www.kaggle.com/competitions/benetech-making-graphs-accessible
Benetech - Making Graphs Accessible | Kaggle
www.kaggle.com
대회 개요
Chart에서 Raw Data를 추출하는 대회
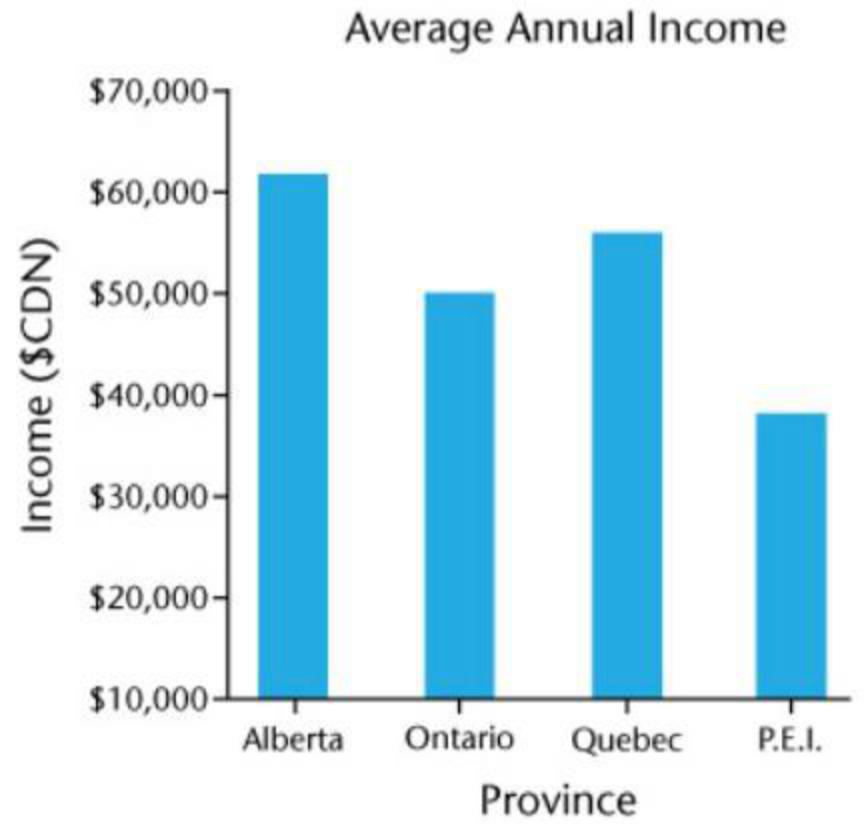
위와 같은 이미지가 존재 할 때 각 데이터에 해당하는 x와 y값을 아래 같이 예측하는 모델을 개발한다.
x,Alberta;Ontario;Quebec;P.E.I.,vertical_bar
y,62023;50355;56288;38621,vertical_bar특이사항
- 5가지 종류의 Chart가 존재한다
- Vertical Bar, Horizontal Bar, Line, Scatter, Dot
- 데이터의 개수는 약 6만개 이지만 이중 실제 데이터는 700장 정도이고 나머지는 프로그램으로 랜덤하게 생성한 데이터이다.
- Test 데이터는 모두 사람이 직접 만든 데이터 이다.
Main Solution
대부분의 사람들이 Image에서 Text 데이터를 추출하는 Pix2Struct 기반의 모델을 사용하고 있음
- Matcha, Deplot의 모델을 finetuning 해서 성능을 올리는 방식을 선택
추가 데이터의 사용이 가능해서 직접 그래프를 생성해서 추가 학습 하거나, ICDAR에서 배포한 그래프 데이터를 사용하는 방식이 상위권을 차지하는 것으로 생각된다
추가적으로 다른 OCR이나 Segmentation 모델을 사용하여 후처리를 해 점수가 특히 낮은 Scatter plot을 보정하는 방식을 취한것으로 생각된다.
진행 과정에서 찾은, 발생한 문제
- 너무 긴 데이터로 인하여 생성해야하는 문장이 짤리는 현상이 발생함
- 원본 데이터 중 일부 데이터는 소수점 아래로 많은 자리수를 가지고 있어 이들 하나하나가 생성하는 토큰을 차지함.
- 모델의 메모리 문제로 인하여 512~768의 길이사이로 학습을 시키는데 이럴 경우 뒷부분이 Preprocess에서 짤리는 경우가 발생
- 모델이 학습에 너무 많은 자원을 소모
- 3080 10G를 학습에 사용하는데 Patch 사이즈를 키우면 Batch size를 1이상 설정이 불가능 했음.
- 1 batchsize 1 epoch 학습당 3시간 이상 소요
- 오버피팅?
- 학습을 완료한 뒤 Text를 뽑아보면 일부 이미지는 제대로 예측하지 못하고 생성의 시작으로 지정한 토큰만 반복해서 뽑아내는 문제가 발생
- Hyperparameter에 매우 민감하게 반응하여 위와 같은 증상이 정말 빈번하게 발생함.
시도해본 방법
1. 적은 자원으로 학습 시도
- Deepspeed 적용
- Deepspeed의 Level 3를 사용하면 Optimizer를 Cpu로 내려서 연산이 가능하여 조금 더 큰 Batch Size를 사용 할 수 있다.
- 다만 GPU 에서 CPU로 일부 파라미터를 내렸기 때문에 Cpu 바운드의 메모리로 데이터 이동을 할 필요가 있고 이에 따른 Context Switching이 발생, 학습속도가 많이 저하되는 현상이 발생한다.
- Cpu에서 내릴 메모리 만큼 추가적으로 Batch 사이즈를 늘리거나, 모델을 더 크게 사용을 하여 성능을 올리는 방식을 취할 수 있다.
- 다만, 원래 모델 사이즈 + 데이터 사이즈가 커서 optimizer만 내렸을 경우 배치의 크기를 늘릴순 없었고, 일부 파라미터를 Cpu로 내려서 학습을 한 경우 Validation Step에서 매우 큰 속도의 저하가 일어났다.
- 기존 512 Patchsize에 2 Batchsize를 사용했었고, 1 epoch당 1시간 반 정도 시간이 소요 되었는데 Deepspeed level 3을 적용하면 약 2시간 정도 시간이 소요되고 Batchsize는 4 까지 사용 가능하였지만, Valid 연산에 시간 소요가 약 10배(시간당 6 s/it 에서 70 s/it) 증가하여 사용하는 의미가 없었다.
- Deepspeed는 포기하고 batch accumulation을 통한 학습속도 향상 및 큰 배치 사이즈 사용하는 것 처럼 유도하였다.
2. 다양한 전처리 시도
3가지의 방식의 데이터 전처리를 통하여 학습을 시도해보았다
- x 예측 후 y 예측을 하는 방식
- x, y 페어를 하나하나 예측하는 방식
- x, y 의 좌표값으로 예측을 하고 다시 되돌리는 방식
2.1 X 후 순차적으로 Y 예측
1번의 경우 아래와 같은 형식으로 Label을 작성 후 finetuning을 진행하였다.
<|PROMPT|><chart type token><X_START>x1;x2;....;xn<X_END><Y_START>y1;y2;....;yn<y_END>이 형식은 일부 Scatter Plot이나 Line Plot의 경우 많은 수의 데이터가 Ground Truth 값으로 존재하여 Text가 자연스럽게 길어지는 현상이 있는데, 이때 X의 Text길이가 너무 길어진 나머지 Preprocessing 과정에서 Label의 Y 값이 짤려버리는 불상사가 발생 하고, 이로 인하여 (x, y)의 짝이 이루어지지 않아 X 또한 제대로 Metric 연산이 되지 않는 현상을 보여주었다.
2.2 X, Y 의 페어 예측
그래서 이를 해결하고자 Deplot모델의 Output을 참고하여 아래와 같이 Label을 수정하였다.
<|PROMPT|><chart type token><LINE_START>x1|y1<tab>x2|y2<tab>....<tab>xn|yn<LINE_END>아래의 방식을 적용 했을때 0.5 초반에서 0.59 까지 성능이 상승 하였으며 조금 더 안정적으로 예측이 가능한 부분을 보여주었다. 다만 여전히 일부 글자를 제대로 인식 하지 못하거나, 그래프의 값을 제대로 유추하지 못하는 경우가 다수 발견되었고, 이를 수정하기 위한 추가적인 후처리 방법을 도입 해 보았지만, 별 다른 성능 향상은 없었다.
2.3 차트의 데이터가 존재하는 부분의 좌표를 예측
차트의 모든 요소 (x axis, y axis, plot bbox, title 등등) 에 대한 좌표값이 제공되었기 때문에 이것을 이용하여 우리가 원하는 Data의 위치를 한번 뽑아보고자 input 전처리를 시도 해 보았다.
<|PROMPT|><chart type token>plot_x1|plot_y1<tab>plot_x2|plot_y2<LINE_START>x1_point|y1_point<tab>x2_point|y2_point<tab>....<tab>xn_point|yn_point<LINE_END>- plot_x1, plot_y1, ploy_x2, ploy_y2 : 그래프가 그려져 있는 부분의 bbox 좌표

어느정도 구현 현실성이 있다고 생각되는 방법이었지만 finetuning 이 제대로 이루어 지지 않아서 일부 Data는 그래프 영역에 대한 BBox가 생성되지 않는 문제가 존재를 했고, 예측해야하는 객체가 명확하지 않은 Line, Scatter의 경우 조금 어긋나는 모습을 보여주었다.

위의 사진과 같이 실제 그래프에 해당되는 부분이 조금 어긋난 것을 알 수 있다.
3. 추가 데이터 사용
아래의 공개 커널을 이용하여 데이터를 100K 추가적으로 생성하여 학습을 시켰다. 다만 Overfitting이 일어나서 실질적인 성능은 기대하지 못하였다.
https://www.kaggle.com/code/brendanartley/benetech-5-chart-types-generator
Benetech: 5 Chart Types Generator
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
상위 Solution 리뷰
대회가 끝나고 현재까지 공유된 상위 Solution의 공통적인 내용을 추합해 보면 아래와 같이 나뉘어 지는것을 볼 수 있었다.
1. 추가 데이터
- ICDAR 등의 기존에 존재하는 Dataset을 가져와서 추가적인 작업을 진행
- 생성데이터의 비중을 줄이거나, 실제 데이터를 증강하여 비중을 늘리는 작업을 진행함
간단하지만 생각을 못한 디테일 포인트가 많은 부분이었다. 대회를 진행하면서 발생했던 문제가 Overfitting이었는데 실제 데이터로만 이루어진 Valid Dataset을 제대로 예측하지 못한다는 부분에서 800장의 실제 데이터와 6만장의 생성 데이터 사이의 분포 차이가 존재했을 것이라는 생각을 하지 못했다.
상위 솔루션들은 가상데이터의 비중을 20% 아래로 줄이거나, 실제 데이터를 Oversampling 또는 추가해서 가상데이터의 약 50%정도가 되도록 맞췄었다. 이외 가상데이터로 한번 더 Pretraining을 진행하고, 이후 실제데이터로 finetuning 하는 방법도 유효 했다고 한다.
2. Pre / Post Processing
- Pre Processing
- Y Axis에 나타나는 유효 숫자의 자리 -1 로 Y값을 전처리 한 뒤 학습
- Post Processing
- Object Detection을 이용한 Data 좌표 추출 및 x, y Axis 추출
- Ocr을 이용한 X axis 보정
- Unet Heatmap, Segmentation을 이용한 Scatter 좌표 보정
- CACHED 모델을 이용한 chart element 탐색
GitHub - pengyu965/ChartDete: Context-Aware Chart Element Detection
Context-Aware Chart Element Detection. Contribute to pengyu965/ChartDete development by creating an account on GitHub.
github.com
많은 상위권 모델들이 대부분 추가적인 Post Processing을 통하여 보정을 진행하였다. 특히 Scatter 의 점 위치를 파악하는 것이 중요했는데 이 부분을 해결하기 위해 다양한 Post Processing을 위한 추가 모델학습을 진행한 것을 볼 수 있었다.
3. More Patch
메모리의 문제로 Patchsize 512, Token length 512로 할 수 밖에 없었는데 대부분의 솔루션은 1024 ~ 4096 까지의 Patchsize, 1024 ~ 2048 token Length를 사용 하였다. 4096의 Patchsize는 40G 메모리에서도 OOM이 발생한다고 누가 질문을 했는데 huggingface의 Gradient Checkpointing 기능을 사용하면 효율적으로 메모리가 감소한다고 답변을 해줘 큰 충격을 받았었다.
실제로 테스트 해본 결과 Patch 512, Token Length 512 에서 10G를 거의 다 사용하는 상태에서 아래 두줄의 코드만 적용했을때 메모리 사용량은 7.7G 까지 떨어졌고, 시간은 1시간 반에서 2시간으로 약간 증가한 것을 볼 수 있었다.
이 상태에서 최대 1024에 Batch 6까지 돌릴 수 있어서 아에 실험이 불가능 했던 더 큰 Patch로 실험이 가능한 것을 확인했다.
model.encoder.gradient_checking_enable()
model.decoder.gradient_checking_enable()아래는 Gradient Checkpointing 에 관한 Article이다